
Human beings as we are, struggle sometimes to think multi-dimensionally about tasks. Our brains seem to have a conscious layer and a sub-conscious layer. Whether you think in words, noise or images, your brain is a single threaded engine with a silent co-processor that can either assist or annoy. Experience has shown that we look at network automation challenges through this shaped lens and try and solve things that makes sense to humans, but not necessarily for mechanized processes.
In an attempt not to lose my own thread, I’ll try and explain some different view points through examples.
Example One: I’m English, Make me some Tea!
Making a a cup of tea is a very English thing to do and the process of making one will suffice for this example.
Let’s look at the process involved:
// { type: activity}
(Start)-><a>[kettle empty]->(Fill Kettle)->|b|
<a>-(note: Kettle activities)
<a>[kettle full]->|b|->(Boil Kettle)->|c|
|b|->(Add Tea Bag)-><d>[Sugar: yes]->(Add Sugar)->(Add Milk)
<d>[Sugar: no]->(Add Milk)
<d>-(note: Sweet tooth?)
(Add Milk)->|c|->(Pour Boiled Water)
(Pour Boiled Water)->(Enjoy)->(Stop)
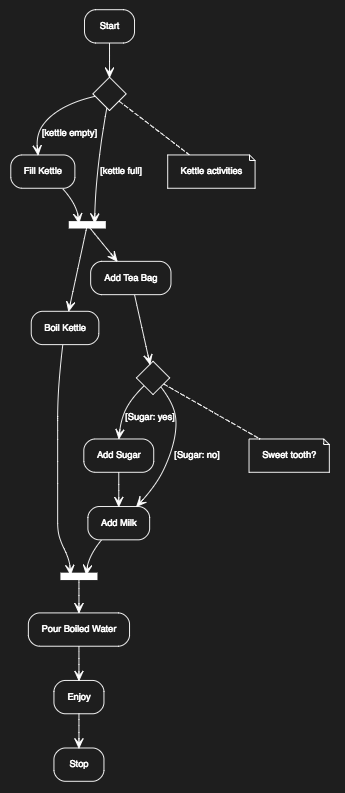
This makes us a relative standard cup of English breakfast tea.
Let’s assume macros exist for milk and sugar quantity and the dealing of a mug or best china has been dealt with.
Let’s analyze from a flow control perspective.
- Human wants tea
- Invoke start
- Check if kettle needs water
- If kettle needs water, fill it, else;
- Boil kettle
- Add tea bag
- If I want sugar, add it (decision)
- Add milk (Ok, some would argue the milk will be scolded)
- Pour boiled water
- Drink
There are interesting points in this flow chart that need pointing out. Boiling of the kettle is a long task, so we can do the other parallel tasks whilst the kettle boils. Even so, adding the tea bag, sugar and milk are still sequential tasks. So we have a long lived task and short sequential tasks giving the impression of efficiency. All tasks then merge and wait for the kettle to finish boiling. Note, no question was asked if the water has boiled as the statement implies you pour boiled water! It can’t be poured boiled water if it hasn’t boiled! The “Pour Boiled Water” can be represented in a self-contained flow-chart and for the purposes of this post is also an asynchronous function.
// { type: activity}
(Start)-><a>[Yes]->(Pour Boiling Water)
<a>-[No]-><a>
(note: Has kettle light gone off?)-><a>
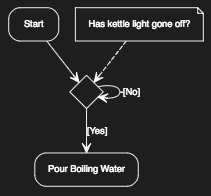
Flow control in this flowchart is sequential in a single time dimension. We could optimize this and the argument against it would be the classic “optimizing the point of constraint”. For one cup of tea, the main flow-chart illustrated in this section is good enough.
Example Two: Surprise Family Visit Tea Factory
It’s a Sunday and the family have arrived. Ten of them. Each take their tea differently and with different tea bags. Although the process is ultimately the same, we now have multiple kettles to cope with the water quantity and a host of ingredients. A sequential model just won’t cut it as the family will moan that their beverages are all different temperatures. Some tasks are sequential and single dimensional and other tasks can be run in multi-dimensions, but all with state injected from the originating dimension.
Two major trains of thought exist here:
- Orchestrated Workflows
- Autonomous Workflows
Orchestrated Workflows are driven from a central “brain” and workflows are typically single threaded with most platforms having the ability to spawn branches if instructed to do so by the workflow creator. Platforms like StackStorm or Salt serve these needs.
In the case of our tea making exercise, a single workflow is triggered, which may spawn jobs both parallel and sequential to boil the kettles, prepare each mug and pour the boiled water. This relies on jobs being spawned, and the orchestrator waiting for each job to exit successfully before carrying on with the next task. The last sentence may require some more explaining but here goes. One cannot pour boiling water without the cups being appropriately laced with tea, sugar and milk (according to the person’s order).
Autonomous Workflows are a little more complicated. These workflows can split from and join each other and can be viewed as sharing data. The whole workflow is applicable to one cup of tea, and as a result, the workflow starts with an identification of all ten cups of tea. Some actions are designated to run once, or in lower numbers than the ten cups of tea. Imagine if programmatically speaking, all ten tea making workflows live in a list type, the first two entries in the list might be responsible for boiling the kettles, although each workflow has the kettle task. The first entry might be responsible for asking and confirming the type of each drink and quantities of milk and sugar. These details are available to all workflows (as the workflows are identical) and the only defining item is a spawn $ID in this case from 0-9. Therefore imagine a “mandate” which looks like below:
drinks:
0: # Drink ID
kind: "engish breakfast"
sugar: 1
milk: "whole"
water_from_kettle: 0
for: "Aunt Dorris"
1: # Drink ID
kind: "earl grey"
sugar: 0
milk: "lemon juice"
water_from_kettle: 1
for: "Uncle Dave"
3: # Etc
...
kettle:
workflow_to_boil:
- 0
- 1
Its possible for each instance of the workflow to get relevant information from the data structure about what it is expected to do, like what drink and if it is responsible for boiling a kettle. Some workflows may require automatic spawning of kettles and quantities of hot water, but for this example this mandate will do just fine.
Creation of the workflow has to be crafted very carefully to ensure the correct decisions are being made at the correct time. Platform by platform, execution style can change however. Ansible will run each task sequentially, dealing with specifics of parallelism when required. For example, one task might be to start boiling the kettle by two of the ‘hosts’, or in our case the drink ID, other tasks are performed like loading of the mugs, then a looped check might happen until the kettles have boiled and both pouring tasks can be completed. This is asynchronous activity versus synchronous activity and has to be managed correctly with correct exit, error and re-try logic.
Networks have a habit of screwing up transitioning to states that require human intervention and any good workflow will provide a “hammer time” revert with a careful mutation, careful being “mutate” and “verify”.
Here is what a modified version of the workflow may look like:
// {type: activity}
(Start)->(Get Drink Mandate)
(Get Drink Mandate)-><a>[kettle $ID empty]->(Fill Kettle $ID)->|b|
<a>-(note: Kettle activities)
<a>[kettle $ID full]->|b|->(Boil Kettle $ID)->|c|
|b|->(Add Tea Bag to $ID)-><d>[$ID Sugar: yes]->(Add Sugar to $ID)->(Add Milk to $ID)
<d>[$ID Sugar: no]->(Add Milk to $ID)
(Add Milk to $ID)->|c|->(Pour Boiled Water from kettle $ID)
(Pour Boiled Water from kettle $ID)->(Enjoy)->(Stop)

The drink and kettle IDs are indexed using the instance $ID of the workflow, so for example, instance 0 boils one of the kettles and deals with making the drink for Aunty Dorris, chatterbox extraordinaire. Each workflow can be used autonomously and in parallel, but with instance 0 and 1 boiling the water and workflows 2-9 consuming water from the kettles boiled by 0 and 1. The kettles in this instance are external and asynchronous services.
Language
I’ve flicked between words like dimensional, sequential, parallel, synchronous and asynchronous. Language in automation mainly comes from control-theory and industrial automation.
I propose the following language for orchestration:
Orchestrated Workflows For workflows requiring central co-ordination. A good example would be coordinating humans to fetch ingredients and handle the ingredient stock. Then the tasks would be executed one by one with central decision making on task progression. Large mechanized processes between organizational units requires this kind of approach. Business Process Management tools fall in this category and workflow engines as previously mentioned Salt, StackStorm etc).
Autonomous Workflows These can be viewed as self-contained workflows. A set of ingredients is despatched with an instruction set. A tool interprets the instruction set and gets on with the job using the ingredients. Some of these tasks might be intra-organizational and CI/CD tooling like Jenkins and GitLab can fall in this category.
I propose the following language for your workflows:
Single-Dimension For workflows that make all decisions in a single plane of logic like making one cup of tea. This could be a task engine like Ansible.
Constraints here might be boiling many kettles and having the first drink go cold whilst finishing the last.
Multi-Dimensional For workflows requiring more than one set of tasks to run in parallel and in different time domains. Cleaning the dishes whilst making the tea would be advantageous to being a good host. A workflow engine could spawn these workflows from an orchestration perspective. Just to confuse you more, the tea making exercise can be spawned ten times with some tasks running just once or tied to an instance ID.
Managing multi-dimensional state can be difficult, so the danger here is not managing error and exit conditions correctly. Instance awareness happens in this mode of operation. This mechanism provides a great way of tying variables to workflow instances like our tea making mandate example (Fig3). In simple terms, an instance can apply it’s own ID as an index into data it needs.
I propose the following language for the tasks that live in the workflows:
Sequential For tasks that require one to finish before the next can start.
This might be taking a mug out of a cupboard and placing it on to the side before throwing in a tea bag, sugar and milk.
Parallelized Sequential For identical tasks that take the same amount of time, like loading ten tea bags into ten mugs.
Another example might be taking mugs out of the cupboard in parallel, then loading them all with tea bags, sugar and milk. After all, we’re making one batch of tea but with multiple cups.
Mixed Parallelized Sequential For workflows containing tasks requiring multiple branches of differing tasks. This could be preparing dinner whilst making the drinks if we carry on with our use cases. The tasks are now varying lengths, but to gain maximum efficiency, how cool would it be to deliver drinks and announce the time of dinner after one “as short as possible” kitchen visit?
Asynchronous For tasks that take a long time to complete, like boiling a kettle. These tasks will have a mechanism that reports their state, or a mechanism to report task completion or error. These mechanisms are accessible platform wide and queryable from any dimension or task. Another example would be having a chef prepare your dinner, give him or her instruction then occasionally shout through to the kitchen.
Closing Words
I can hear screaming and the reason for that is, choice complicates the approach. What about a “Centrally Orchestrated, Multi-dimensional, Parallelized Sequential” workflow? Now you’re talking coffee shop grade automation with two very simple constraints: till speed and worst drink preparation time. It would be like being in a cafe but being served as if you were the only person in it.
It’s better to be armed with knowledge than fumble your way through. My advice is always to draw this out on a whiteboard or on paper. I draft everything in UML which includes the programmatically created diagrams in this post.
When it comes to design, split workflows and tasks apart and do the simplest thing, always. In our tea example, if Aunty Dorris is chatting everyone’s ear off, then your guests may require your refreshments faster and therefore remove as many bottlenecks as possible. If Uncle Dave, ‘Dare Devil Extreme’ is sharing a story about base jumping, they might not care about time, but eventual delivery within the time constraints of the story will be well received.
As the number of components increases, the higher the number of error and recovery scenarios you have to consider. A centrally orchestrated, multi-dimension with asynchronous and parallelized sequential tasked workflow breathes in needs to be designed with reliability in mind. Mechanisms like watchdog timers, auto-remediation for predictable errors and hard mutation reverts based on unrecoverable errors all help. When there is an unrecoverable failure, the creator should have a path to invoke human assistance. One example might be to use a ChatOps module or call a phone with a pre-recorded message! Imagine Google’s Assistant ringing you? Cool or eery? Multi-dimension automation without central orchestration still needs recovery plans, but with fewer things to go wrong, it’s more likely a single task will fail rather than the orchestration engine itself.
In short, the more stuff you have, the more fragile it becomes. With great automation powers, comes great potential failure, but also fantastic gains if done correctly! Sorry Uncle Ben, this needed closure.
This post has mainly focussed on an easy to explain “drink making” workflow and network automation really isn’t any different. A workflow is a workflow, domain differences withstanding. Great network automations come from people who truly understand their own domain. Despite being wordy, the language used in this post should help you to define how the workflow behaves and identify the correct way to execute tasks. Out of experience, half the battle is knowing where to start and that is with drafting workflows. The tools and platforms can be identified later and should never lead discussions of process mechanization.
Until the next time, thank you for reading and please leave comments or ask questions.
Helpful Notes
Theory of Constraints: https://en.wikipedia.org/wiki/Theory_of_constraints
Control Theory: https://en.wikipedia.org/wiki/Classical_control_theory