
This post acts as the introduction for two other posts, which cover Junos data collection tools for Kafka and InfluxDB. The code is open-sourced and licensed under MIT. Both applications are ready for release and I’ve spent considerable spare time building and testing both pieces of software.
To Go or not to Go
Back in yesteryear, I used to be a C developer and enthusiast. Thanks to the infamous K&R C book, it made perfect sense when I needed a language that provided syntax what I thought of at the time as one level higher than assembly. Roll the clock forwards a decade and Go has become my ‘go to’ (multi-pun intended) language. It’s powerful from its simplicity, easy to debug and super easy to observe when things aren’t going as you planned. The concurrency capabilities seem to make perfect sense and development cycles are short thanks to the powerful “batteries included” tool-chain. Building binaries couldn’t be easier and building containers for the likes of Docker is a piece of cake. Thanks also to the language’s popularity, tools like Travis-CI are easy to work with. Powerful enough to do almost anything, easy enough to learn in days and offers grace when handling concurrent logic flows.
The CSP side of Go is just fantastic. This article doesn’t cover it, but I’m a huge fan!
For example, Junos runs FreeBSD and building binaries to run on Junos is as easy as one can imagine. Whether you develop on OSX, Linux or Windows, the process is identical: GOOS=freebsd go build. Aint that simple?
Just one note here, on veriexec enabled Junos it isn’t enough to just build the binaries; it needs packaging too!
Inspiration
Working for vendors (at the time of writing, Juniper networks) I get a fair amount of insight to the real problems network operators (SP/enterprise/telcos/data centres) face daily simultaneously whilst trying to evolve their strategy. Thanks to the current automation craze, any set of data applied to the network mutating its state, comes from a decision to make the change (the when), the desired graph end state (the what) and input mechanisms that trigger mutation (the how). This post acts as an umbrella for two other posts based on the “when” and how to correlate what when is. The problem with “when” is that of multi-dimensions. Time moves on whilst you’re in the past and looking forwards. A different way of looking at this would be, correlation tasks over time, become a squeeze-box sliding window of observation. Real-time distributed systems apply back pressure on to correlation systems as state-machines hold in various positions waiting for signals that trigger transitional shifts to the end-state. The only reasonable means to go forwards is make the data pipelines as fluid as possible. Kafka and InfluxDB are perfect weapons for this challenge and treat correlation as one or more components that do not lock up these data systems.
From a “signal-to-event” correlation process, I’ve began to think correlation is best served from a micro-services architecture, with each correlation being it’s own application. Currently the trend is to use a platform that holds a lot of state whilst correlating. That means if it crashes, all of that is lost too. I’ll write something about that soon! For now and the purpose of this post, the focus is squarely on extracting the data from Junos.
Exploring the Process
Kafka and InfluxDB have their own requirements for the insertion of data.
With respect to data, Kafka requires that the producer writes data to a topic. InfluxDB requires the producer knows the database name, tag and field sets.
I’ve seen frustration around InfluxDB when there isn’t enough tag or field information to discern data sources, leading to data overwrites when the time stamp is the same. You do not have this issue with Kafka due to Kafka working with offsets within a topic within a partition within a cluster (unless you forcibly overwrite the offset!).
When it came to the design of the collector, I followed the IP Engineer learning charter and discovered most of the work was done for me. Here’s the UML diagram of what I needed to do.
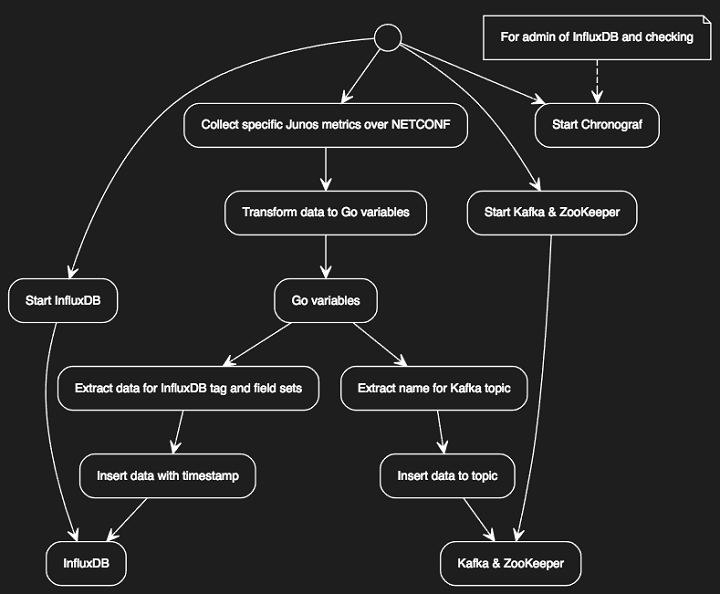
// Here is the YUML that created the diagram above
// Here is the YUML that created the diagram above
// {type: activity}
(start) -> (Start Kafka & ZooKeeper) -> (Kafka & ZooKeeper)
(start) -> (Start InfluxDB) -> (InfluxDB)
(start) -> (Start Chronograf)
(note: For admin of InfluxDB and checking) -> (Start Chronograf)
(start) -> (Collect specific Junos metrics over NETCONF) -> (Transform data to Go variables) -> (Go variables)
(Go variables) -> (Extract name for Kafka topic) -> (Insert data to topic) -> (Kafka & ZooKeeper)
(Go variables) -> (Extract data for InfluxDB tag and field sets) -> (Insert data with timestamp) -> (InfluxDB)
After a short hunt around using my Google powers, I found Daniel Czerwonk’s Junos exporter for Prometheus. This appeared to do all of the hard work of data acquisition and all I needed to do was replace the Prometheus code with Kafka and InfluxDB client function calls and do some handling for clean exit.
What I did next was:
- Used my fork of go-netconf to acquire the data from Junos.
- Added the Influx & Kafka clients to Daniel’s code and removed traces of Prometheus.
- Wrapped the code with channels for starting and stopping routines and sharing data between Go routines.
- Added command line arguments to each application and the ability to use SSH keys as well as plain text user/password credentials.
Both applications were relatively easy to put together. I had a concern of memory leaks for a short while, but after using ‘gops’ for a few days, I put those worries out the back of my brain. Any application that launches multiple Go routines and is truly asynchronous, will behave in a way that feels organic. As tasks are dealt with by routines and as context switching happens, it can feel very fluid with waves of growth and shrinkage over time.
For instructions on using both the Junos Kafka and InfluxDB applications, use the links below. Each application is command line argument driven and is easy to build and install. Each application also comes with Dockerfiles for ease of use.
Exporter idea
Modern operational processes demand that metrics like device, interface, process and service be obtained from the network nodes for a variety of uses like machine-learning based prediction and event-driven automation. Junos offers a solid NETCONF interface that can be used to obtain operational and configuration information as well as newer gRPC based telemetry subsystems. On Junos systems that do not offer a telemetry subsystem, data can be reliably obtained from NETCONF, transformed and published in a required format to time series databases and streaming platforms. Junos as of yet cannot do this today without some off-box help. This is where applications like the below come in to play.
Applications listed in the following sections can be run in Docker containers or as foreground applications, connect to the NETCONF service on a Junos instance via username/password credential pairs or SSH keys and connect to the target data producer APIs which at the time of writing are InfluxDB and Kafka.
One might be wondering about the use of Go here and the answer is simple and comes in the form of bullet points:
- Go is simple
- Go does not have version 2.x or 3.x differences that will break things
- Go compiles in to a target OS specific build, exceptionally easily
- Go empowers the user to create custom collectors and compile them in to the binary
- Go offers powerful concurrency right out of the box without thinking about dodgy parallelism libraries
Collectors are very easy to create and included in the build. Take a look inside the collectors directories of each project to figure out how to create and customize your own. A number are included covering the major topics.
jinfluxexporter InfluxDB & Junos link
Note: Requires that InfluxDB has been built with uint64 support
jkafkaexporter Kafka & Junos link
Close
I’ve spent considerable time working on both applications and will support them best effort. Pull requests are welcomed for bug fixes, feature additions and general help!
Disclaimer
Please note, each of these applications have been published by me directly and are by no means supported by Juniper Networks. They will be supported best effort through GitHub. You use them squarely at your own risk.