
Ghost2logger: Design Thinking
It’s funny how you never hear “That was easy!” after a person or a team have finished creating a piece of software. Creating software presents many technical and personal challenges. Invariably, even before a design is drafted, decisions in your mind’s eye are made on architecture, frameworks and patterns to take advantage of specific programming languages or personal styles. This is especially true in highly charged political environments where gaining ground is essential. Having open ended questions in those environments could be seen as a sign of weakness and answers often come in the form of “this language solves this challenge”. However, do not exclude a language from solving requirements, based on the fact it solves some challenges elegantly.
Despite Go taking some abuse for a lack of ‘things’ like generics or the inevitable ‘it doesn’t do it the way I want to do it’, I admire the language for sticking to its core beliefs of keeping things simple, which gives users a huge amount of power. Simplicity, performance and clear use of design thinking in the core language delivers this power. You do not need a JVM or CLR to run code thanks to embedding of the runtime. Compilation is rapid, the tool chain is rich and helpful to users of all levels and the community is vibrant and helpful. Go provides C like gains with ease of use; a result from removing complexity like pointer arithmetic and building in concurrency mechanics from day zero. This paragraph isn’t to convince you to adopt the language, it just describes why I like it and why I chose to use it for this project. Go seems to gift me every time I use it, with a sense of achievement and ever expanding knowledge of its capabilities.
So, what is Ghost2logger and what can/will it do for you?
Ghost2logger: Who and pre-requisites
Ghost2logger was initially conceived to enable network engineers to trigger automations based on syslogs, which in turn are generated from some network event. That could be a port up/down event, a protocol state change or even a resource warning like CPU or memory. When an automation that is triggered from these syslog messages aims to resolve a pre-conceived situation, we call it “auto-remediation”. Moving on a little with the thoughts, it applies to syslogs in general and not just ones generated and emitted from network devices.
Network engineers have traditionally used built-in features in vendor provided network operating systems, as their building blocks. They have also manipulated network routing protocols using vendor provided knobs and levers, but not the messaging sub-systems and protocols directly in code. They understand the Internet Protocol intimately but not necessarily the running and maintaining of services on a Linux operating system. This is not always the case, but it is a general rule of thumb. The key point being as the industry moves forward, complexity increases and we’re asking the network engineering community to think about things they’ve never had to think about before. Therefore, as the industry moves forward and we demand successful automation deployments, we have to make tools as simple and usable as possible. Ghost2logger is one of those tools that should be simple to use with obvious gains from the onset.
Ghost2logger: Technical Requirements
A simple service that consumes UDP transported Syslog messages and converts ‘matched’ messages to a webhook RESTful POST call (to a third party system). The match criteria is also posted to Ghost2logger via another RESTful call. I need to state at this point, Ghost2logger already exists as a ‘very alpha’ application. This is the first blog post of a series that covers its design, creation, and the journey to a stable release including supporting artefacts. The idea is that the Ghost2logger service consumes a high volume of syslog events, sifts through them, and forwards events of interest to a consumer. The original idea came from a StackStorm requirement and originally it was called “Go ST2 logger”, which was not very memorable. By adding the aesthetic ‘h’, Ghost2logger was born.
StackStorm is an event driven automation platform. It allows you to consume inputs and trigger something to happen (something being an action or workflow). StackStorm is agnostic and made domain specific by installing ‘packs’, which are collections of input things, decision things and output things. Ghost2logger is an input thing for StackStorm.
Ghost2logger’s requirements can be broken down as follows:
- Receive one thousand syslog messages per second
- Messages are compared against match criteria to result in “messages of interest”
- Match criteria is received via a RESTful interface (100x match criteria)
- Matches are transmitted to a RESTful API (webhook on third party system)
- Must support time aggregated complex events
If you’re thinking “1000x syslog messages per second and 100x match criteria sounds like guess work”, you are correct, it is. I have no idea what the requirements are, so I’m setting them at this level to give us something to work against. After testing, our actual capabilities might be higher.
With respect to point five, the only one not clearly self-describing, a time aggregated complex event can be described as “a number of identical syslogs entering Ghost2logger over a configurable X amount of seconds, will be transmitted to the destination as a single operation”.
So the next question is, if we move away from microservices to a monolith application, is Go still the right way to (excuse the pun) go? I’m going to answer yes, due to the fact that Go has excellent concurrency and CSP(Communicating Sequential Processes) capabilities if used the right way. Just because Go can be used to create excellent micro-services, it doesn’t exclude itself from a monolith exhibiting multiple behaviours.
If you know Go, your mind might explode with ideas at this point. “Channel here, message queue there, composite type here…” and Go can do all of these things, just let’s not go that far yet. One of things that came out of my recent Go training is, using Go’s various mechanisms sometimes result in surprising and unexpected results.
Let’s take our design one step further with some more details:
-
Receive one thousand Syslog messages per second through a configurable UDP port (by default is 514).
-
Receive match criteria through RESTful POST calls (with basic authentication) and build a table. The data type right now is unknown, but we know we need a data structure that will hold a set of criteria matches.
-
Use an API call generator to post data to a third party RESTful API using an authentication key.
-
To be run on Linux (based on StackStorm compatible platforms), either in the foreground or as a systemd service and as a Docker container.
Our initial integration third party target is StackStorm, which offers webhooks, direct RESTful API calls to actions and workflows and another option to create a ‘sensor’ which we can fire events at, which in turn emits an internal event. This sensor has to be constructed in Python and has to follow the StackStorm design guides. In scope of the requirements, I will create one that offers a very specific RESTful API to receive the Ghost2logger events. Note, it will not be covered in this post. At a high level we don’t care about the detail as the POST call can be a configuration item. Detail is always interesting though!
Below is a graphical representation of the requirements above.
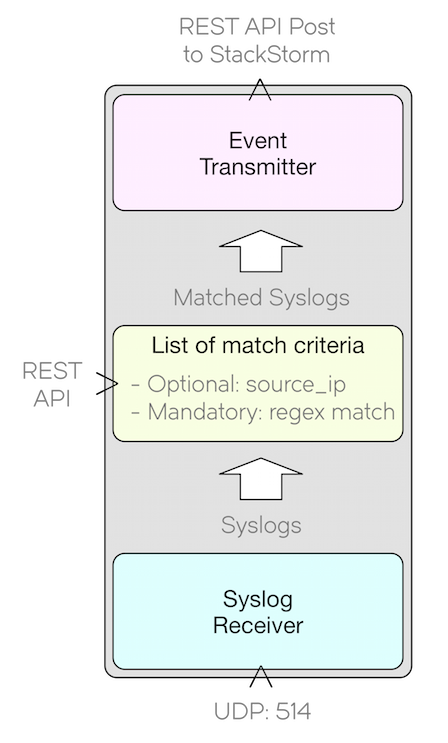
Even though we have our requirements above, there are more decisions we have to make as we go through exploring each of them. Nothing is concrete right now apart from our requirements.
At this point, it might seem premature to discuss project structure, but deciding right now to take a package oriented design approach will prove valuable when we start building the actual code. There are many gains from this approach as described in the Package Oriented Design article.
This provides a strong set of foundations to build upon. Here’s a rough idea of how I want the project to be laid out going forward.
github.com/arsonistgopher/ghost2logger
├── CONTRIBUTORS
├── LICENSE
├── README.md
├── cfg/
├── cmd/
│ └── ghost2logger
│ └── ghost2logger.go
├── internal/
│ ├── criteria_rest_rx/
│ │ └── criteria_rest_rx.go
│ ├── webhook_tx/
│ │ └── webhook_tx.go
│ └── criteria_db/
│ └── criteria_db.go
└── vendor/
└── stuff/
This structure will evolve and effort will be made to adhere to the design approach laid out by Bill Kennedy.
Ghost2logger : Building the Foundations This blog post is being used as the production grade design, so naturally it can be assumed that all thoughts are shared including the fun problems experienced along the way.
Here are our high level operational requirements:
- Run as foreground application or as a systemd service
- Compile for Linux & Darwin and provide associated Dockerfiles
- Logging with toggles in a config file for logging level and handling complex events
Simple! Let’s move forward one step at a time and aim to solve the above before we touch anything else.
Iterative Construction The first thing I normally do is prove out each component or idea into a set of something I call ‘scratches’. These scratches are prototypes and prove out ideas in a bare bones fashion. It’s working code, but will not be production grade. Each scratch is created to answer questions I have in terms of functionality, usage and patterns. They may or may not be testable. Scratches are just my pet-name for prototypes and the name has no relevance to anything else.
This approach allows me to prove out ideas and move beyond potential sticky-situations before I’m knee deep in code. Sticky situations lead to technical debt at a later phase and I’m keen to avoid that. Scratches also provide teams with talking points when doing proposing how to solve a problem. Working example code reveals things that whiteboard concepts just cannot uncover.
Scratches For Ghost2logger, I will create the following ‘scratches’ as I do not have immediate answers. These scratches may or may not build on each other. Some might just be minimal proof-of-concepts.
- Basics: Code and configs that allows instantiation as a foreground application or daemon
- Logging pattern: Create one logger, accept logs through a channel and remove fragile dependencies
- Configuration File: Add configuration and parse it.
- In memory data structure: To store match criteria that is analysed against each syslog received.
- Receive Syslogs: Opening a UDP socket and handling Syslogs to meet our receive rate.
- Syslog Criteria Match: Scan each syslog message against the match criteria
- Emit event: to a third party RESTful API
During construction, I will aim to keep the code free of global state following on from the articles by Peter Bourgon and Dave Cheney. Ghost2logger will be created to avoid magic, which excludes packages that maintain their own (potentially the logging package).
Finally for this section, I will also create unit tests. Whilst not quite a religious follower of unit tests, they are valuable for ensuring code functions correctly and for avoiding regressions. I’m not religious about approaches like TDD (Test Driven Development) but I will write tests to ensure correct behaviour of the functions.
Ghost2logger : Scratching Things Out
Scratch(Basics): Here we deal with the most basic requirements: to instantiate the application as a foreground application or damon. We will test on a VM (Virtual Machine) that uses systemd and also Docker, allowing us to test as a foreground service on Ubuntu and CentOS. This combination covers the Linux varieties we need to be compatible with and the different instantiation types.
Our test pipeline looks like the below. After each deploy, we check the logs.
- Deploy to a virtual-machine and start as a systemd daemon (Ubuntu 16.04 / RHEL (CentOS) 7)
- Start as a foreground app (easy to prove)
- Deploy to Docker, start as foreground app (Ubuntu 16.04 / RHEL (CentOS) 7)
This can get repetitive and I might even go as far as writing a set of scripts or even workflows to deploy my software artifacts. One step at a time though. Let’s prove this out bit by bit. As our super app needs to log to STDOUT, STERR and to the journal system, we need to make sure the logs will appear where and when we expect them. That requires a logging package that can courier logs to systemd’s journal. After a bit of research, I chose the coreos go-log package. Based on feedback from reviewers or from the community, I might want to swap it out in time for something else. That means my design needs to lightly couple to the logging package, hence the assumption of needing to create the ‘logging pattern’ scratch(2).
For our super contrived example scratch(1), I’ll introduce a basic HTTP server. It’s easy to use, acts as a long lived server and makes our logging a bit more fun. This is a perfect test tool without getting too deep around any of our other requirements.
Here is the Go code for scratch(1).
// This code is an attempt to build a simple demo of a foreground, Docker and journald app with basic logging.
//
// Our contrived example launches a HTTP server and offers a route for '/'.
// Logs are generated at various stages of service/app start/stop/run and servicing of calls.
//
// Copyright David Gee 2017, arsonistgopher.com
// This is released under the CRAPL License: http://matt.might.net/articles/crapl/
package main
import (
"fmt"
"net/http"
// This package gives us good logging capabilities inline with our requirements.
// It claims to handle stdout/stderr/journal!
"github.com/coreos/go-log/log"
// This is our foundation service.
// This allows us to run as a foreground application as well as systemd service.
"github.com/kardianos/service"
)
// Required in order to instantiate the methods required for the service.
type program struct{}
// This is a HTTP handler and not part of the service package.
func handler(w http.ResponseWriter, r *http.Request) {
log.Info("[Scratch1] Request Received for: ", r.URL)
fmt.Fprintf(w, "Hi Dave, I love you man!")
}
// This is part of the service package and represents our Start() entry point.
func (p *program) Start(s service.Service) error {
// Start should not block. Do the actual work async.
log.Info("[Scratch1] Entered p.Start(s)")
// Call/launch run as a Go Routine
go p.run()
return nil
}
func (p *program) run() {
// Our basic run() method
log.Info("[Scratch1] Entered p.run(s)")
// Register the HTTP handler
http.HandleFunc("/", handler)
log.Info("[Scratch1] Registered handler() for HTTP / call")
log.Info("[Scratch1] Serving http://localhost:8181")
// ListenAndServe does not return, allowing our GR
http.ListenAndServe(":8181", nil)
}
func (p *program) Stop(s service.Service) error {
// Stop should not block. Return with a few seconds.
log.Info("[Scratch1] Entered p.Stop(s)")
return nil
}
func main() {
// Pretty comments
svcConfig := &service.Config{
Name: "Scratch1 Service",
DisplayName: "Go Scratch1 Service",
Description: "This is the Scratch1 multi-purpose award winning service and foreground app.",
}
// Create a program struct
prg := &program{}
// Create a new service
s, err := service.New(prg, svcConfig)
if err != nil {
log.Fatalln(err)
}
if err != nil {
log.Fatalln(err)
}
// This runs the exported Run() method which calls Start() in turn.
err = s.Run()
if err != nil {
log.Fatalln(err)
}
}
The above code exercises Daniel Theophane’s service package and also the coreos go-log package. Some self-criticism here, does it gracefully stop the HTTP server? Nope. Logging is also somewhat direct and tightly bound to the go-log package. This is a scratch and does not address this kind of stuff (yet). In order to test our code for our requirements, the keen reader will note we’re missing a systemd service file and Dockerfile. Fear not. They’re here. Directly below is the systemd service file.
[Unit]
Description=Scratch 1 Service Test
Documentation=http://TODO
[Service]
Type=simple
ExecStart=/opt/linux_scratch1
StandardOutput=null
Restart=on-failure
[Install]
WantedBy=multi-user.target
Alias=scratch1.service
If you’re not familiar with systemd, this file is super simple and almost self-descriptive. ExecStart allows us to specify where the binary is in order to start it and the Restart keyword in this case allows us to restart the binary on a failure. Cool.
What about our Dockerfile?
I’ve done some reading up on Dockerising Go apps and there are more than a few methods. The decisions to make have been boiled down to the below at this stage of exploration. I also need to add I work on MacOS if you’re wondering what this “cross compilation” rhetoric is about.
- Do I compile in the container or cross compile and copy the binary to the container?
- If I compile in the container, do I vendor the dependencies or get them from the internet?
Whilst we’re playing with scratches, I’m keen to keep things super simple. The Dockerfile below allows us to make use of Go’s vendor experiment (introduced in 1.5 and beyond 1.7 is permanently enabled). I copy the required packages into the vendor directory and that’s that from a Docker perspective. The go build process will use the vendored dependencies and will not require downloading a chunk of the Internet every time we want to build. I think this is quite cool and saves some work.
FROM golang:latest
WORKDIR /go/src/app
COPY . .
RUN go build -o main .
CMD ["/go/src/app/main"]
EXPOSE 8181
Our next step is to build the binaries for OSX (I like to run this stuff locally and on the target machines), Linux and Dockerised on a Linux container. The below shows the build excerpts.
Whenever the application is instantiated, it opens a port on TCP :8181 and listens for HTTP GETs on the URL ‘/’. As the GET is executed, you’ll note logs appear from scratch1.
go build
cp scratch1 darwin_scratch1
GOOS=linux go build
cp scratch1 linux_scratch1
Next job is to copy the files to a target Linux server.
scp scratch1.service linux_scratch1 name@server
On the target machine, copy the scratch1.service to /etc/systemd/system and the binary to /opt/ Once you’ve copied them across, then you can start the systemd service and check for logs.
sudo systemctl start scratch1
sudo systemctl is-active scratch1
journalctl -u scratch1 -f
At this point open your browser and if you’re called Dave like me, then you’re in for a treat.
Next, stop the systemd service with the below command and start it as a foreground app.
sudo systemctl stop scratch1
cd /opt
./linux_scratch1
Use ^ctl + c to stop the foreground app.
Back on your dev machine.
docker build -f Dockerfile . -t arsonistgopher/ghostscratch1
docker run -d -p 8181:8181 --name scratch1 arsonistgopher/ghostscratch1
At this point open your browser and call ‘/’.
You should be able to access the port and check the Docker logs.
docker logs -f scratch1
For scratch(1), we have built it, launched it in systemd, launched it as a foreground application, launched it in a Docker container and have checked for log outputs when we call HTTP GETs on the URL ‘/’. Can we consider this scratch(1) to serve its purpose? I’m going for yes.
Scratch 1 Complete
In part one, we’ve covered a lots of ground and have got the basics working and then some. We’ve exercised out a service package, a logging package, used Go’s cross-compilation, deployed a systemd service and a Docker container, all for free and for the glory of doing it.
Part 2 will aim to deliver a nicer way to log and I’ll also look at automating the build pipeline to introduce CI/CD concepts. We might not progress enough in part 2 for unit and functional tests, but they will come!
This is a great starting point and set of foundations for Ghost2logger.
Access to the code and all of the various files (Dockerfile, systemd service, binaries and main.go) is all via GitHub.
Useful Reading for Part 1
This is the Google document for the Go vendor experiment introduced in 1.5. https://docs.google.com/document/d/1Bz5-UB7g2uPBdOx-rw5t9MxJwkfpx90cqG9AFL0JAYo/